Area of Interest
My research interests lies in the areas of network modeling, optimization and design of edge intelligence. In particular, I have been focusing on topics including Machine Learning, SDN Load-balancing, Supercomputer Scheduling and Metaheuristic algorithm designs, etc.
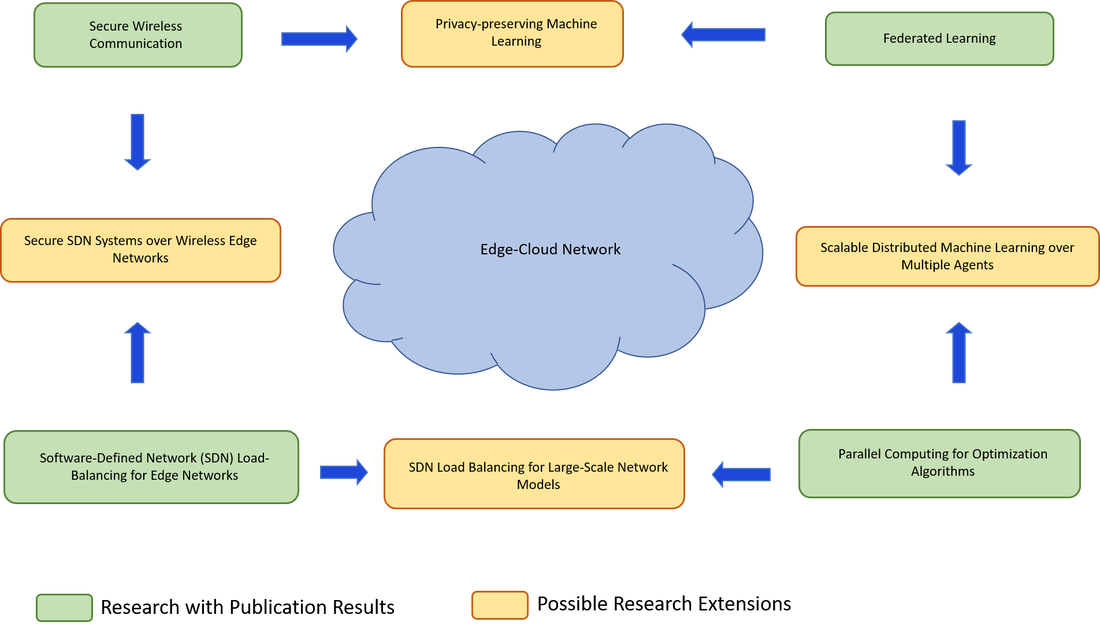
- Contents within the green box refer to the researches I have been working on. The corresponding research results have been published and listed below.
- Contents within the yellow box demonstrate possible directions of future research extension based on the results of my previous works.
Introductions to my works are represented as follows:
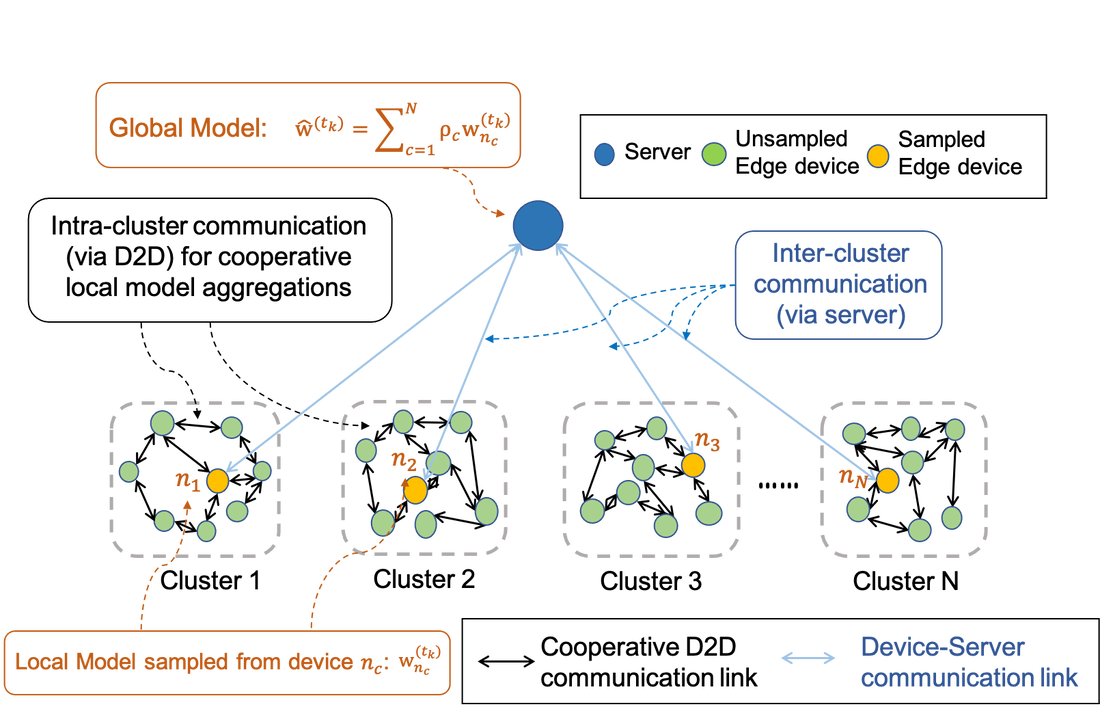
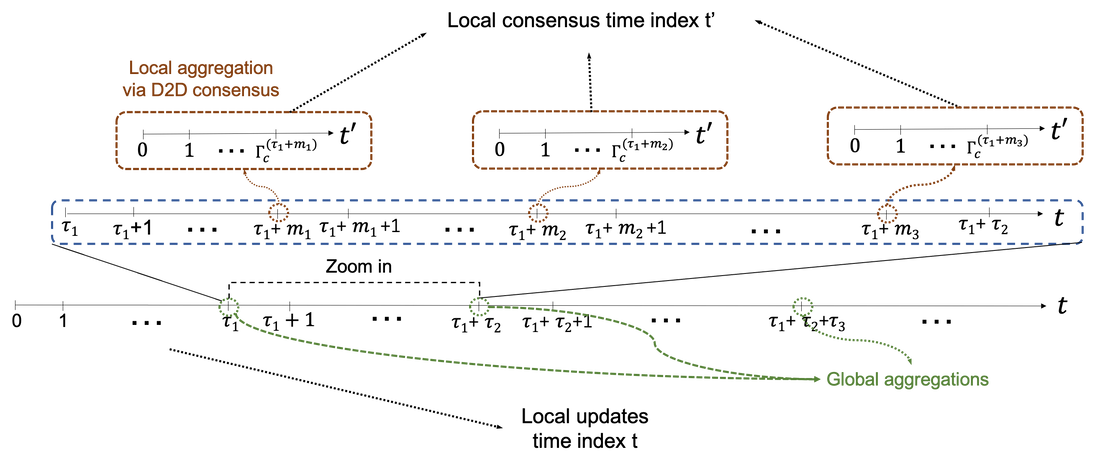
Semi-Decentralized Federated Learning with Cooperative D2D Local Model Aggregations
|
Federated learning has emerged as a popular technique for distributing machine learning (ML) model training across the wireless edge. In this paper, we propose two timescale hybrid federated learning (TT-HF), which is a hybrid between the device-to-server communication paradigm in federated learning and device-to-device (D2D) communications for model training. In TT-HF, during each global aggregation interval, devices (i) perform multiple stochastic gradient descent iterations on their individual datasets, and (ii) aperiodically engage in consensus formation of their model parameters through cooperative, distributed D2D communications within local clusters. With a new general definition of gradient diversity, we formally study the convergence behavior of TT-HF, resulting in new convergence bounds for distributed ML. We leverage our convergence bounds to develop an adaptive control algorithm that tunes the step size, D2D communication rounds, and global aggregation period of TT-HF over time to target a sublinear convergence rate of O(1/t) while minimizing network resource utilization. Our subsequent experiments demonstrate that TT-HF significantly outperforms the current art in federated learning in terms of model accuracy and/or network energy consumption in different scenarios where local device datasets exhibit statistical heterogeneity.
|
Related Works:
1. Frank Po-Chen Lin, Seyyedali Hosseinalipour, Sheikh Shams Azam, Christopher G. Brinton and Nicolò Michelusi, “Semi-Decentralized Federated Learning with Cooperative D2D Local Model Aggregations,"IEEE Journal on Selected Areas in Communications, vol. 39, pp. 3851 - 3869, 2021.
2. Frank Po-Chen Lin, Seyyedali Hosseinalipour, Sheikh Shams Azam, Christopher G. Brinton and Nicolò Michelusi, “Federated Learning Beyond the Star: Local D2D Model Consensus with Global Cluster Sampling,"in Proc. IEEE Global Communications Conference (IEEE Globecom 2021), Dec, 2021.
2. Frank Po-Chen Lin, Seyyedali Hosseinalipour, Sheikh Shams Azam, Christopher G. Brinton and Nicolò Michelusi, “Federated Learning Beyond the Star: Local D2D Model Consensus with Global Cluster Sampling,"in Proc. IEEE Global Communications Conference (IEEE Globecom 2021), Dec, 2021.
Federated Learning with Communication Delay in Edge Networks

|
The edge intelligence paradigm seeks to scale up machine learning (ML) model training and inference by distributing these processes across edge devices spread in the network. Federated learning has received significant attention as a potential solution for distributing ML at the edge. This work addresses an important consideration of federated learning in these scenarios: communication delays between the edge nodes and the aggregator. A technique called FedDelAvg (federated delayed averaging) is developed, which generalizes the standard federated averaging algorithm to incorporate a weighting between the current local model and the delayed global model at each device during the synchronization step. Through theoretical analysis, an upper bound is derived on the global model loss achieved by FedDelAvg, which shows strong dependency of learning performance on the value of the weight and learning rate. Experimental results on a popular ML task indicate significant improvements in terms of convergence speed when optimizing the weighting scheme to account for delays.
|
Related Works:
1. Frank Po-Chen Lin, C. Brinton and N. Michelusi, "Federated Learning with Communication Delay in Edge Networks," IEEE Global Communications Conference (Globecom), Dec. 2020.
2. David Nickel, Frank Po-Chen Lin, Seyyedali Hosseinalipour, Nicolo Michelusi and Christopher G Brinton, “Resource-Efficient and Delay-Aware Federated Learning Design under Edge Heterogeneity,” 2022 IEEE International Conference on Communications Workshops (ICC Workshops), Seoul, South Korea, May 16-20, 2022.
2. David Nickel, Frank Po-Chen Lin, Seyyedali Hosseinalipour, Nicolo Michelusi and Christopher G Brinton, “Resource-Efficient and Delay-Aware Federated Learning Design under Edge Heterogeneity,” 2022 IEEE International Conference on Communications Workshops (ICC Workshops), Seoul, South Korea, May 16-20, 2022.
Software-Defined Network (SDN)


|
Although the openflow-based software defined network (SDN) architecture can ease the workload of network control and management and separate it from the switch/routing operations, a computation-resource limited controller can still be congested by heavy flows and then experiences serious delay. To enhance network scalability and reduce computation delay on SDN networks under Quality of Service (QoS) requirements, a hierarchical edge-cloud SDN (HECSDN) controller system design is proposed with three features. First, by sharing computational resources in the edge and the cloud, the system architecture provides a flexible mechanism for devices to allocate their computational tasks according to traffic loads. The second feature is to design a queueing model of the proposed architecture. The model description of the networking architecture enables the network designers to quickly estimate the performance of design without considerable time and cost in experimental setups. Third, derived from the queueing model, an efficient load-balancing algorithm satisfying QoS requirements or fairness allocation for different applications in the HECSDN architecture is proposed. This newly-developed multi-tier controller system has been proved to be effective even when working on a large-scale SDN, without sacrificing the overall performance.
|
Related Works:
Parallel Processing Supercomputers

|
Supercomputing has been indispensable in the unstoppable trend of high-speed computing evolution. This work aims at improving its running efficacy by introducing a new two-step scheduling approach. Based on the analysis of large historical data, we provide an accurate runtime estimation scheme using Instance-Based Learning (IBL) in the first step. Then a swarm intelligence based scheduling (SIBS) method is proposed to optimize the scheduling performance in terms of total runtime makespan and fair resource allocation. A method comparison on a dataset from the ALPS supercomputer, which consists of 804k workload data in 2016, shows that our proposed method outperforms the most commonly used strategy – Extensible Argonne Scheduling System (EASY).
|
Related Works:
1. Frank Po-Chen Lin and Frederick Kin Hing Phoa, Runtime Estimation and Scheduling on Parallel Processing Supercomputers via Instance-based Learning and Swarm Intelligence," International Journal of Machine Learning and Computing, vol. 9, 592-598, 2019.
Wireless Localization

|
It is essential to enhance the speed and accuracy of the localization process to gain the robustness and instantaneous properties and to adapt from the practical environment of a confidence band. In this paper, we proposed a new received signal strength indicator-based method to construct a realtime confidence band, which was composed by multiple confidence region sets in a multivariate normal distribution, associated to a target’s trajectory for location-based services. Based on the concept of weighted positioning circular algorithm, we designed a new objective function to take into consideration the signal disruptions of the surrounding environments. The characteristics of the state of motion for the moving target were then inferred from the status of each confidence region. In order to speed up the localization process to obtain the real-time estimate of the confidence band via our objective function, we proposed in this paper a swarm intelligence-based localization optimization algorithm, which was modified from the standard framework of a novel swarm intelligence-based evolutionary algorithm.
|
Related Works:
1. Frank Po-Chen Lin and Frederick Kin Hing Phoa, “An Efficient Construction of Confidence Bands via Swarm Intelligence and its Application in Target Localization,” IEEE Access, vol. 6, 8610 - 8618, 2018. (Q1, SCIE, 24/148)
Parallel Computing on Evolutionary Algorithms

|
Algorithm parallelization diversifies a complicated computing task into small parts, and thus it receives wide attention when it is implemented to evolutionary algorithms (EA). This works considers a recently developed EA called the Swarm Intelligence Based (SIB) method as a benchmark to compare the performance of two types of parallel computing approaches: a CPU-based approach via OpenMP and a GPU-based approach via CUDA. The experiments are conducted to solve an optimization problem in the search of supersaturated designs via the SIB method. Unlike conventional suggestions, we show that the CPU-based OpenMP outperforms CUDA at the execution time. At the end of this paper, we provide several potential problems in GPU parallel computing towards EA and suggest to use CPU-based OpenMP for parallel computing of EA.
|
Related Works:
1. Frank Po-Chen Lin and Frederick Kin Hing Phoa, “A performance study of parallel programming via CPU and GPU on swarm intelligence based evolutionary algorithm,” International Conference on Intelligent Systems, Metaheuristics & Swarm Intelligence (ACM-ISMSI 2017), Hong Kong, China, March 25-27, 2017.
Secure Wireless Communications

|
Physical layer security in wireless communication deals mainly with unauthorized users, eavesdroppers, and/or jammers. It is crucial for wireless network due to its broadcast nature and the channel state information (CSI) is easily acquired by unauthorized receivers. Thus, eavesdroppers can easily obtain information by utilizing the estimated CSI. In this paper, we propose a secure channel estimation method which includes two components, i.e., the designs of pilot signals and estimator for time division duplex orthogonal frequency division multiplexing systems. According to analyses, the CSI can be estimated successfully at the authorized receiver. Eavesdroppers cannot obtain the CSI even if they are close to the transmitter or the authorized receiver.
|
